

Análisis de datos con Python

En este artículo estaremos detallando los diferentes métodos utilizar con la librería pandas y otras para el análisis y gráfico de datos con Python. Podemos visualizar dicho código en el siguiente repositorio de github y recomendamos leer las bases en el nivel básico.
Introducción
Cabe mencionar que realizaremos el análisis de datos con Python haciendo uso de archivos con extención .ipynb con jupiter en el editor VSCode. Esto se debe a que estaremos usando dataframes (tablas de datos con id autoincremental). De igual modo, puede usar la extención .py y utilizar “print” para visualizar los datos/gráficos.
Una de las cosas que debemos tener en cuenta es que, a veces, se pueden presentar problemas con la codificación del archivo a utilizar. Es decir, para el habla hispana usamos tildes u otros caracteres especiales en muchas palabras. Por lo tanto, la codificación UTF-8 es fundamental aplicarla.
Para ello simplemente debemos ir a la ubicación de nuestro archivo ejemplo.csv, le damos clic derecho en “Abrir con..” y elegimos el bloc de notas. Una vez hayamos hecho los cambios o agregado los caracteres correspondientes, le damos en “Guardar como..” y abajo en “Codificación” debemos elegir UTF-8 como se muestra en la siguiente imagen:
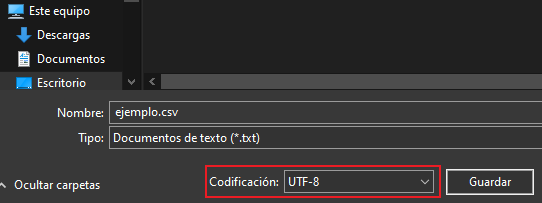
Una vez hecho esto no deberíamos seguir teniendo problemas.
Conceptos Básicos
A continuación, y para introducirnos en el análisis de datos, empezaremos viendo la aplicación de lectura a distintos tipos de archivos con Python. Para ello, primero debemos importar nuestro módulo de la siguiente manera:
import pandas as pd
Leer diferentes formatos
Lerr archivos EXCEL:
Con respecto a una columna o pestaña:
test = pd.read_excel(“file_excel.xmlx”,“colum1”)
Con respecto a un índice. Por ejemplo 3:
test = pd.read_excel(“file_excel.xmlx”,“3”)
Leer archivos JSON:
test = pd.read_json(“file_json.xmlx”,“colum1”)
Leer archivos CSV:
Como este tipo de archivo se usa a partir de dataframes, por convención lo que se hace es colocar esta variable con el nombre de “df”:
df = pd.read_csv(“file.csv”)
En adelante estaremos usando este último modelo para el análisis de datos en cada práctica y ejemplo con Python.
Introducción básica
import panda as pd
df = pd.read_csv(“dataframe.csv”)
df
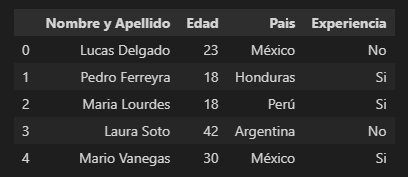
Lectura de columnas
Si deseamos leer una columnas sin espacios:
df.Edad
Caso contrario:
df[‘Nombre y Apellido’]
Juntar varias columnas:
df[[‘Nombre y Apellido’, ‘Edad’]]
Verificar Filas y Columnas con shape
Recordemos que el archivo dataframe.csv es el que vimos en las consignas anteriores. Por lo tanto, haciendo uso de shape veríamos lo siguiente:
df.shape
Out:
(5,4)
#Solo Filas
df.shape[0]
Out:
5
#Solo columnas
df.shape[1]
Out:
4
Ver una cierta cantidad de datos
Hay archivos que poseen una gran cantidad de datos. Para ello, las siguientes funciones nos ayudarán con la visualización que nosotros queramos.
Si queremos ver los primeros 4 registros:
data = pd.read_csv(“datos.csv”)
df.head(4)
Si queremos ver los últimos 4 registros:
data = pd.read_csv(“datos.csv”)
df.tail(4)
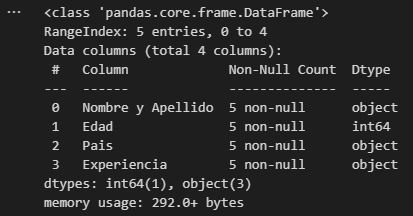
Ver información con respecto a los tipos de datos de un archivo
Teniendo en cuenta nuestro dataframe:
df = pd.read_csv(“file.csv”)
Debemos realizar:
df.info()
Análisis de datos
Introducción
Para verificar la cantidad de registros (o filas) que se repiten hacemos uso de la función value_counts().
Para saber la cantidad de veces que se repite la Edad:
df.Edad.values_counts()
Out:
Edad
18 2
23 1
19 1
30 1
Name: count, dtype: int64
Con respecto al País:
df.Pais.count_values()
En el caso del Nombre y Apellido:
df[‘Nombre y Apellido’].value_counts()
Ordenar la información
Ordenar la información ASC/DSC
De forma Ascendiente por País:
df.Pais.value_counts(ascending=True)
De forma Descendente por País:
df.Pais.value_counts(ascending=False)
En el caso de haber valores nulos:
df.Pais.value_counts(ascending=True, dropna=False)
Ordenar la información de diferentes maneras
De manera alfabética:
df.Pais.sort_values()
De forma alfabética eligiendo columnas:
df.sort_values(by=[‘Nombre y Apellido’,’Edad’])
Uso de Filtros
Filtrar por Condiciones
Con respecto a un País
df[df.Pais == «México»]
Con respecto a un País y Experiencia
df[(df.Pais == «México») & (df.Experiencia == ‘Si’)]
Usando “contains”
df[df.Pais.str.contains(«México»)]
Usando “startswith” por palabra
df[df.Pais.str.startswith(«H»)]
Cambiar y Ordenar según el índice
Cambiando el Índice
df.set_index(‘Pais’)
Si queremos que dicha salida quede fija en el valor de la variable df hacemos:
df.set_index(‘Pais’, inplace=True)
Si queremos volver al valor original
df.reset_index(inplace=True)
Ordenar según el índice ascendente (por defecto)
df.Pais.sort_index()
Ordenar según el índice descendente
df.Pais.sort_index(ascending=False)
Localizar por índices y etiquetas
En el caso de querer localizar por etiquetas, podemos hacerlo por País y sus datos
df.loc[df.Pais == ‘México’]
Con un índice
df.iloc[2]
Con varios
df.iloc[[1,3,0]]
Mostrar un rango de índices [n:m]
df.iloc[1:5]
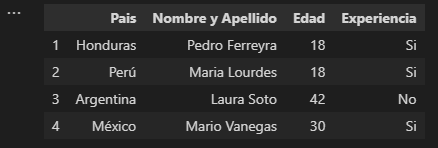
Recordemos que dicho resultado se expresa tomando los valores desde n hasta m-1 como sudece con la función range().
Agrupación y análisis de Información
Ordenar la información
Agrupar de acuerdo a la experiencia
list(df.groupby(‘Experiencia’))
Agrupar de acuerdo al País
list(df.groupby(‘Pais’))
Visualizar mejor los datos
for key,value in list(df.groupby(‘Experiencia’)):
print(key)
print(value)
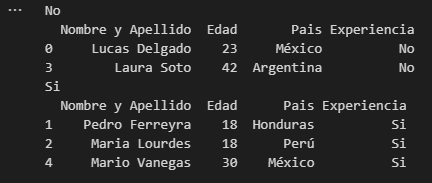
Agregar información
Usar información extra para nuestros datos
df.groupby([«Edad»,»Nombre y Apellido»,»Pais»]).agg([«min»,»max»,»count»])
Podemos agregar una columna como referencia
df.groupby([«Edad»,»Nombre y Apellido»,»Pais»]).agg({‘Experiencia’:[«min»,»max»,»count»]})
La información aquí se basará primero en los tres criterios (“Edad, Nombre y apellido, Pais”) y, en base a estos datos, los ordenará de acuerdo al max, min y count según la “Experiencia”.
Este tipo de funciones son muy utilizados, y se visualizan mejor, cuando tenemos una gran cantidad de columnas y registros.
Dar formato a nuestros datos
En base a dos Países, vamos a buscar si ambos tienen coincidencia con personas sin Experiencia.
Para esto agrupamos dos paises variable ‘info’ de la siguiente manera:
info = df[((df.Pais ==’Argentina’) | (df.Pais ==’México’)) & (df.Experiencia ==’No’)]
info
Como vemos, esto nos trae como resultado las personas sin experiencia de ambos píases. Ahora bien, si deseamos ver la información paso a paso y más detallado, podemos hacer uso de las siguientes funciones.
Juntamos los datos de los dos Países en la variable ‘juntar’.
juntar = df[(df.Pais ==’Argentina’) | (df.Pais ==’México’)]
juntar
Lo siguiente nos indicará que, en base a dichos países, uno sí tiene Experiencia.
agrupar = juntar.groupby([‘Pais’,’Experiencia’]).size()
agrupar
Para mejorar aún más la visualización podemos usar unstack.
mejorar = agrupar.unstack(‘Experiencia’)
mejorar
Usando la librería Matplotlib para graficar
En esta sección nos introduciremos en los distintos gráficos que nos ofrece la librería Matploitlib para el análsis de datos con Python. Como así también otras que veremos en el apartado de gráficos. Para ello, haremos uso de nuestro archivo finance_data.csv el cual representa una tabla con distintos productos y artículos a modo de ejemplo.
Cabe mencionar que dicho archivo se encuentra codificado en UTF-8. Recuerde que al principio de este artículo explicamos como realizar dicha configuración.
Introducción
Importamos a través de import especificando pandas as pd, matplotlib.pyplot as plt, seaborn as sns y especificamos los datos de la tabla:
tabla = pd.read_csv(«finance_data.csv»)
Recuerde que puede visualizar los primer 5 datos haciendo tabla.head() o si desea ver todos los datos del artículo ‘chocolate’ puede hacer tabla_ch = tabla[tabla.Artículo == ‘Chocolate’] como hemos visto anteriormente.
Ahora bien, supongamos que nos piden los datos sobre la cantidad de artículos con respecto a la categoría “Hogar” disponibles en nuestra tabla. Entonces vía la variable info:
info = tabla[tabla.Categoría == ‘Hogar’]
info.Artículos.value_counts()
info
Out:
Artículo
Escoba 31
Escobillón 25
Detergente 24
Lejía 24
Limpiavidrios 18
Bombilla 18
Trapo Piso 13
Para graficarlo hacemos lo siguiente:
info.Artículos.value_counts().plot(); #Usamos comilla para una mejor visualización
Out:
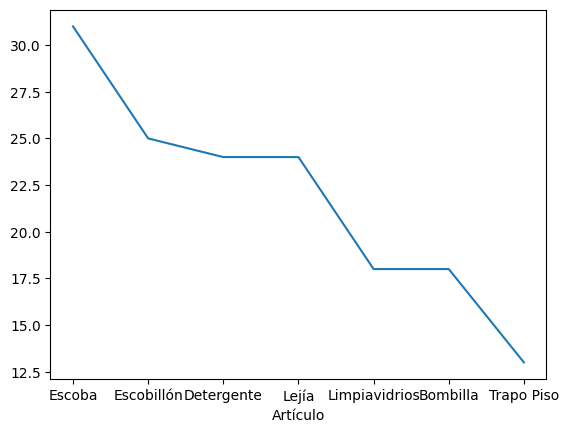
Si queremos arreglar la superposición de palabras en la variable independiente x del gráfico, podemos hacer:
info.Artículo.value_counts().plot(figsize=(10,5), color=‘red’);
plt.plot(3,24,»o»);
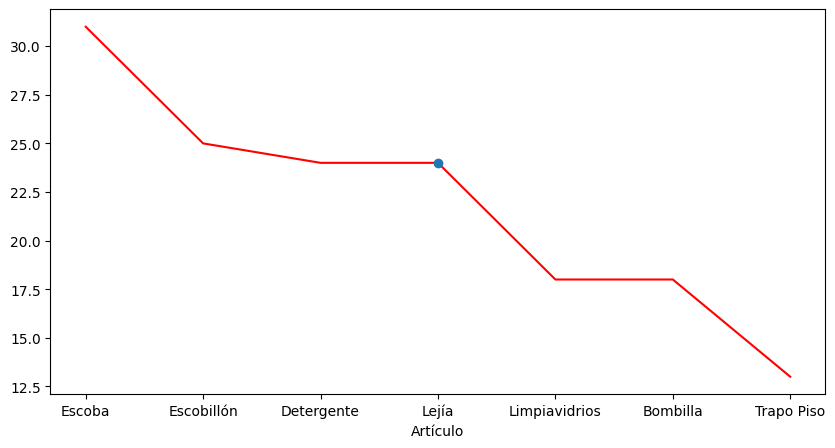
De esta manera le asignamos el valor y=10 a la cantidad e x=5 a los Artículos. Agregado a esto, y para cualquier gráfico, podemos asignarle distintos colores mediante color=‘tipo_de_color’.
La posición del circulo, con la función plt.plot(), corresponde a la ubicación 3=‘Lejía’ (recordemos que Python empieza a contar desde 0) y la posición y=24. Con “o” especificamos el circulo.
Tipos de gráficos
Teniendo en cuenta las variables info y tablas, a continuación veremos algunos de los gráficos más utilizados para el análisis y ciencia de datos con Python y otros campos.
Gráficos de Barras
Barras verticales
info.Artículo.value_counts().plot(kind=’bar’);
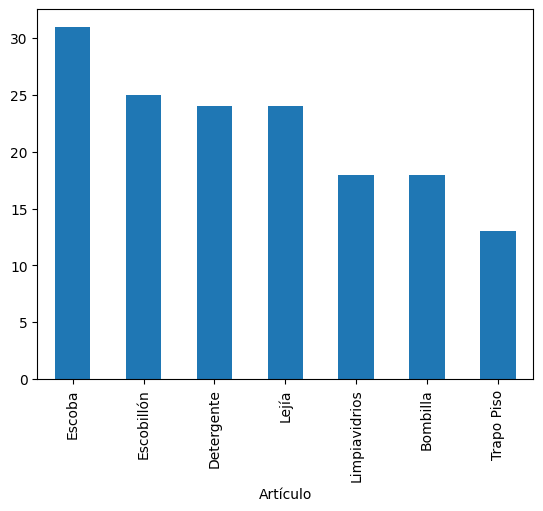
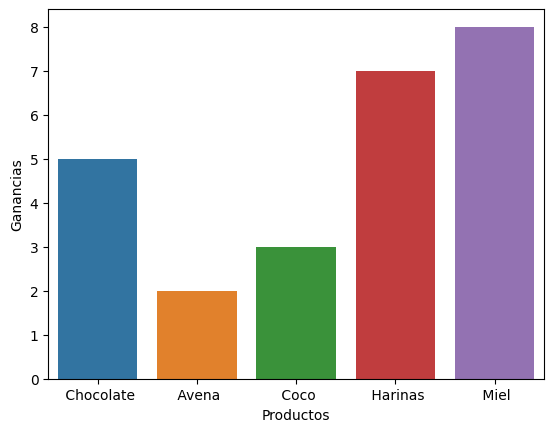
Barras verticales con distintos colores. Vemos que hemos utilizado un archivo llamado “productos.txt”.
productos = pd.read_csv(«productos.txt»)
sns.barplot(x=’Productos’, y=’Ganancias’, data=productos);
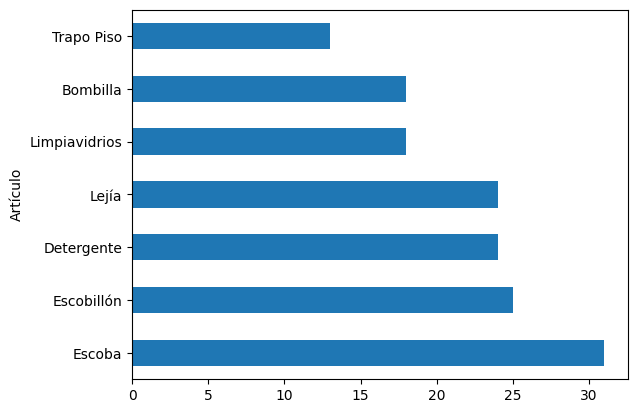
Barras horizontales
info.Artículo.value_counts().plot(kind=’barh’);

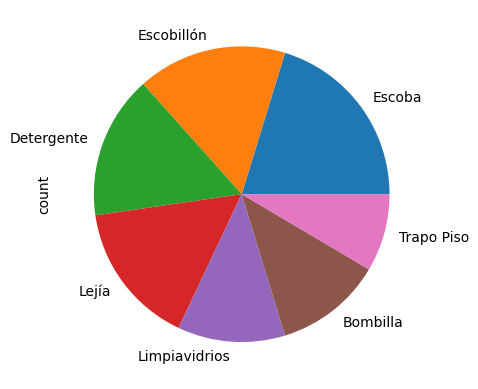
Gráfico de Pastel
info.Artículo.value_counts().plot(kind=’pie’);
Gráficos de Coordenadas
sns.scatterplot(x=’Unidades’, y=’Ganancia’, data=tabla);
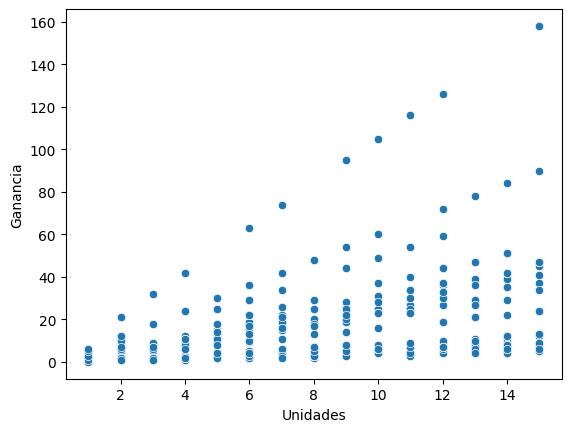
Gráfico básico de variables
Df = pd.DataFrame({‘x’: [10, 8, 10, 7, 7, 19, 10, 12],’y’: [6, 4, 5, 5, 7, 9, 10, 10]})
Df.plot()

De esta manera hemos aprendido a manejar datos, modificarlos y graficarlos a través de las librerías mencionadas.

